Object Detection(객체 탐지) 는 딥러닝 중 컴퓨터 비전 분야에서 가장 어플리케이션 단에서 인기있게 연구되고 있는 분야입니다. 실생활 어플리케이션에도 많이 적용되는 만큼 이 기술의 발전 속도가 정말 대단합니다.
제가 처음 컴퓨터 비전에 관심을 갖게 된 계기도 이러한 객체 탐지 기술의 놀라운 성능 때문이였습니다.
이번 포스트에서는 이러한 객체 탐지 모델을 어떻게 구성하고 이것이 무엇인지에 대해 살펴보겠습니다.

위 사진은 주어진 사진에서 각 객체(Object)를 탐지 후 --> Bounding Box --> 이를 분류하는 image classification 문제로 이어집니다.
한 장의 이미지를 놓고 이미지를 Input 으로 받아 Class를 분류하는 Image classification과는 다소 다르지만 크게 다르다고도 할 수 없는 부분입니다.

Object Detection 모델은 크게 Region Proposal based 그리고 Regression/Classification based 두 가지로 나뉘는데, 크게 보자면 현재는 Region 기반의 방법이 다소 느린 단점을 극복하기 위해 현재의 1-way 기반의 Single process 기반의 객체 탐지 모델들이 많이 제안되고 있습니다.
본 글에서는 Single Shot MultiBox Detector(SSD) 를 기준으로 Object Detection 모델에 대해 설명을 해보겠습니다.
Overview of Object Detection
Concepts
- Single-Shot Detection : 이전의 객체 탐지 모델은 크게 2가지 Stage로 분류됩니다. Object Localization 과 Classifier. 하지만 이러한 step-by-step의 방식은 계산적으로 비용이 많이 들며 real-world application에는 적용되기 힘든점이 있습니다. 또한 속도적인 면에서도 이점을 가져가지 못합니다. 따라서, 현재 제안되고 있는 모델들은 대부분 Single-Shot, 즉 localization과 classification을 동시에 수행하는 방식론들이 많이 도입되고 있습니다.
- Multiscale Feature Maps : 이미지 분류는 기본적으로 마지막 단계의 컨볼루셔널 네트워크의 Output을 기준으로 softamx(classification head)를 통과시켜 각 클래스의 Score(Probability)를 계산합니다. 하지만 객체 탐지 모델에서는 중간 단계의 컨볼루셔널 네트워크의 Output 또한 사용될 수 있습니다. 왜냐하면, 한 가지 이미지에 대한 Representation을 다양한 scale에서 계산할 수 있기 때문에 성능적인 부분을 fine-tuning할 때 세밀한 조정이 가능하도록 해줍니다.
- Priors : feature map을 기준으로 aspect ratio와 scale에 따라 미리 계산된 박스들입니다. 이 박스들은 ground truth 박스에 맞도록 세밀하게 조정됩니다.
- MultiBox : 예측된 객체 탐지 bounding box 를 regression problem으로 만들어주는 일종의 기술입니다. 즉, 각 박스의 좌표값 (x,y,w,h) 들을 regression 문제로 다루어 ground truth 값들과 대응 시켜주는 작업입니다. 또한, 각각의 예측된 박스들에 대해 다양한 object type에 대한 score가 부여됩니다. (예: horse 0.94). 이 작업은 Priors 를 기준으로 수행되는데, 대부분 객체가 없는 경우가 많습니다.
- Hard Negative Mining : 이 작업은 False Positive(객체가 아닌데 객체라고 판단하는 경우) 를 선택하고 모델이 이러한 샘플들을 배우도록 하는 작업입니다. 즉, 모델의 입장에서 정확하게 식별하기 어려운 negative샘플들을 모으는 작업입니다. 객체 탐지 입장에서, 실제로는 대부분의 박스들이 객체를 포함하고 있지 않기 때문에 이러한 작업은 negative-positive 사이의 불균형을 해결하는 역할을 합니다. 대표적으로는 Online mining algorithm(OHEM) 같은 알고리즘이 제안되었습니다. 참고로, SSD에서는 Positive:Negative 를 1:3 비율로 minning합니다.
- Non-Maximum Suppression(NMS) : NMS라고 주로 불리우는 이 작업은 한 Location이 주어졌을 때 multiple priors 들이 겹쳐 있을 수 있습니다. 따라서, 한 객체에 다양한 중복된 박스들이 생길 수 있습니다. NMS 는 이러한 중복된 예측값을 없애주는 것인데, box의 score별로 정렬 후 가장 큰 maximum score를 갖는 박스 하나를 구하는 중복제거 알고리즘입니다.
Some definitions
- Bounding Box : 그냥 박스입니다. Fig 1에서 보이는 노란색, 빨간색 처럼 객체를 포함하고 있는 박스를 바운딩 박스(Bounding Box) 라고 합니다.
- Boundary Coordinates : 박스를 나타낼 수 있는 가장 좋은 방법은 Pixel 좌표를 이용하는 것입니다. 다음과 같은 970x546 이미지가 있을 때, 고양이가 갖는 Bounding Box의 좌표는 Fig 3과 같이 나타낼 수 있습니다. 하지만 반대로, 실제 input dimension을 모를 경우, Fig 4. 와 같이 상대 비율로도 나타낼 수 있습니다.


많이들 쓰이는 방법 중 또 다른 방법은, (g_c_x, g_c_y, g_w, g_h) 형식으로 나타내는 것인데 (g_c_x, g_c_y) 는 bounding box 의 center coordinate이고 , (g_w, g_h) 는 bounding box의 너비와 높이입니다.

- Jaccard Index or Intersection-over-Union(IoU) : IoU는 두 개의 박스에 겹쳐있는 부분을 측정하는 일종의 Metric입니다. 전체 박스의 면적 대비 겹쳐있는 부분을 계산하는 것입니다. IoU가 1이라는것은 두 개의 박스가 같다는 것을 의미하며 0은 완전히 다른 박스라는 것입니다.

Single-Shot Detector (SSD)
SSD는 CNN 으로 이루어진 Object Detection Model로 2016.11 에 publishing 되었습니다. 새로운 SOTA를 갱신하여, VOC, COCO dataset에서 74% mAP 와 59FPS 을 달성하였습니다.
SSD는 크게 3가지 convolutional network로 구성이됩니다.
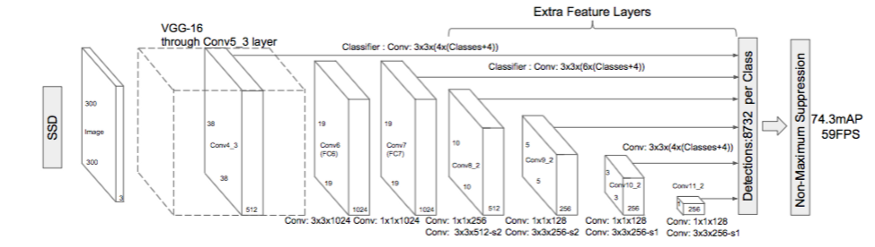
- Base convolutions : lower-level feature map을 제공하는 image classification 구조입니다. 예, VGG16
- Auxiliary convolutions : higher-level feature map을 제공하기 위해 base network 위에 conv net이 붙은 구조입니다.
- Prediction convolutions : feature map 에서 object의 위치를 찾고 분류하는 conv net입니다.
SSD 페이퍼에서는 SSD300, SSD512 두 개의 다른 모델에 대해 소개합니다. 뒤에 붙은 300,512는 fixed-size의 input을 의미합니다. (i.e. 300x300 input을 처리하는 SSD300 Model) 논문에서는 SSD512 가 SSD300에 비해 조금 더 나은 결과를 보여줍니다. 먼저 이 세가지 conv에 대해서 살펴 보도록 하겠습니다.
Base convolutions
Base network로는 VGG16 과 같은 기존의 Image classification에서 사용되는 구조를 사용한다고 했습니다. 그 이유는 VGG16과 같은 구조가 image classification에서 이미 좋은 성능을 보여주었기 때문에, object detection에서 각 bounding box의 object에 class를 분류하는 문제를 해결하기에 적합하기 때문입니다. 따라서, 같은 구조를 사용하여 detected bounding box의 score를 정확하게 예측할 수 있는 수단으로 사용합니다. 좀 더 확실히 말하자면, Object detection에서의 image classification문제는 전체 이미지 중 일부분을 분류하는 Localized image classification으로 볼 수 있겠습니다.
SSD author는 ILSVRC ImageNet 으로 pre-trained 된 VGG16 network를 base conv 로 사용했습니다. 이러한 base conv는 제작자에 따라 다양하게 선택될 수 있습니다. 예를 들면, ResNet, MobileNet, DenseNet, EffcientNet 등 다양한 pre-trained 모델의 weight값들을 transfer learning을 통해 object detection모델을 학습시킬 수 있습니다.

위 VGG16 network는 224x224x3 의 이미지를 하나의 클래스로 분류하기 위한 Image classification에 적합하도록 구성되어 있습니다. 우리는 이러한 구조를 Object Detection에 적합하도록 일부 구조를 변경해야합니다.
- Input size를 지정해야합니다. 본 글에서는 SSD300을 기준으로 설명하므로, Input size 는 300x300 입니다.
- 3th pooling layer(75->32.5)에서는 ceiling function 을 사용합니다.
- math.ceil(37.5) = 38 but, math.floor(37.5) = 37 - 5th pooling layer 를 nn.MaxPool2d(kernel_size=2, stride=2) 에서 nn.MaxPool2d(kernel_size=3, stride=1)으로 바꿔줍니다. 이를 통해 마지막 Pooling layer에서는 input dimension이 절반으로 줄어들지 않습니다.
- Object Detection에서 VGG16 network의 Classification 을 담당하는 Fully Connected Layer는 필요하지 않습니다. 따라서 FC8 Layer를 완전히 없애고, FC6과 FC7 network를 ConvNet(Conv6, Conv7)으로 변경해줄것입니다.
- FC6 의 Input은 flatten 된 7 * 7 * 512 이고 output size 는 4096 입니다. 따라서, conv6은 7,7 kernel size와 4096 output channel을 갖게 설계하면 됩니다.
- FC7 은 4096의 input 을 받아 4096으로 출력하면 되므로, conv7은 1,1 kerner size를 갖고 4096의 output channel으로 설계하면 됩니다.
하지만, 여기서 생각해 볼 점은 conv6과 conv7 의 parameter수가 4096으로 상당히 많다는 점입니다. 저자는 이러한 문제점을 해결하기 위해 subsampling을 했습니다. subsmapling을 위해 Atrous 알고리즘을 사용했는데, 여기서 Atrous는 쉽게 이해하면 dialiated kernel로 보시면 될 것 같습니다.
- Conv6 은 1024 filter를 사용하며, 각 디멘션은 (3,3,512) 입니다. (4096,7,7,512) -> (1024,3,3,512) 로 변경
- Conv7 은 1024 filter를 사용하며, 각 디멘션은 (1,1,1024) 입니다. (4096,1,1,4096) -> (1024,1,1,1024) 로 변경
논문에서는 이 subsampling을 사용했을때 결과는 똑같았지만, 연산량이 줄어들어 speed가 20% 가량 증가했다고 합니다.

위의 4가지 조건을 적용하여 변경된 구조를 이용하여 새로운 VGG16 network를 설계합니다.
Auxiliary Convolutions
VGG network에 higher-layer 의 feature map 추출을 위한 conv net을 추가로 적용해야합니다. 2개의 Layer 를 가진 총 4개의 conv net을 적용합니다. stride=2 를 가진 각각의 Pooling layer을 통해 size reduction이 적용되며 conv8_2, conv9_2, conv10_2, conv11_2 로 부터 각각 feature map들을 가져옵니다.

Prediction Convolutions
앞서 구한 6개의 Feature map(conv4_3, conv7, conv8_2, conv9_2, conv10_2, conv11_2) 을 통해 bounding box 의 offset을 구해 객체를 탐지해야합니다. 또한 탐지 된 객체의 Class를 분류하여 Score를 측정해야합니다.
이 작업을 위해 각 feature map 에 2개의 convolutional layer가 필요합니다.
- Localization Prediction : conv layer with (3,3) kernel 을 각 location에 적용, padding=stride=1. 각 Prior에 4개의 Filter를 사용함. 4개의 Filter는 prior로 부터 예측된 bounding box의 offset (g_c_x, g_c_y, g_w, g_h) 을 계산함. 쉽게 말하면, 주어진 이미지에 객체가 어디있는지 offset을 찾는것.
- Class Prediction : conv layer with (3,3) kernel 을 각 location에 적용, padding=stride=1. filter 수는 class의 숫자임. 쉽게 말하면, Bounding Box에 있는 Object의 Class를 분류하는 것.
자세히 살펴보기 위해, 두 conv layer의 output을 도식화하여 보겠습니다. Feature map conv9_2의 output은 5x5x256 입니다. 이 output의 Localization prediction layer는 파란색으로 나타내었고, Class prediction layer는 노란색으로 나타나있습니다.

각각의 목적에 맞게 prediction conv를 적용하게 되면 LOC 9_2 는 feature map conv9_2의 bounding box 위치를 regression 하는 목적에 맞게 학습되고, CLS 9_2 는 해당 객체가 무엇인지를 판별하는 역할을 합니다. 여기서 주목할 점은 "Channel" 입니다.

conv 9_2 의 feature map을 기준으로 24 channel의 output이 생기면 각각의 4개의 채널은 한 개의 Bounding Box에 대한 Location 정보(g_c_x, g_c_y, g_w, g_h) 를 담고 있습니다. 다시 말해, 24channel 은 6개의 bounding box 정보를 담을 수 있죠. 위 그림과 같이 1x1x4 feature map은 빨간색 grid의 bounding box를 가리키고 있습니다. 따라서, 각 채널의 값은 prior에 대한 encoded offset으로 볼 수 있습니다. Class prediction 도 똑같습니다.

예를 들어, cat 과 dog 를 분류하는 이진 분류 모델이라고 했을때 object detection의 전체 클래스는 "3" 이 됩니다. 왜냐하면, 객체를 포함하지 않는 "Background"를 생각해주어야합니다. 따라서, n_classes 가 3일 때, 1x1x3 의 cell 은 각 class에 대한 prediction score를 나타내고 있습니다. predicted score를 softmax를 이용해 정규화 해준 후 가장 높은 갚의 score를 걸러내는 NMS를 적용하여 Object Detection을 수행한다고 생각해주시면 됩니다.
참고. input size를 넘어서는 overshoot grid에 대해서는 clipping이 수행되기 때문에 걱정하지 않으셔도 됩니다.

SSD300 에서는 8732 개의 predicted box를 사용하기 때문에(6개의 layer를 source로 사용할 때 기준, 5776 + 2166 + 600 + 150 + 36 + 4=8732), 각 Localization 과 Classification prediction convolution 은 각각 위 그림과 같이 stacking되어 prediction에 사용됩니다.
다음 글에서는 SSD를 training하기 위한 내용에 대해 알아보도록 하겠습니다.
Reference
본 포스트는 개인 공부를 위해 https://github.com/sgrvinod/a-PyTorch-Tutorial-to-Object-Detection을 옮겨 일부 수정한 것입니다.